开会时CPU 飙升100%同事们都手忙脚乱记一次应急处理过程
告警
正在开会,突然钉钉告警声响个不停,同时市场人员反馈客户在投诉系统登不进了,报504错误。查看钉钉上的告警信息,几台业务服务器节点全部报CPU超过告警阈值,达100%。
赶紧从会上下来,SSH登录服务器,使用 top 命令查看,几个Java进程CPU占用达到180%,190%,这几个Java进程对应同一个业务服务的几个Pod(或容器)。
定位
- 使用 docker stats 命令查看本节点容器资源使用情况,对占用CPU很高的容器使用 docker exec -it <容器ID>bash 进入。
- 在容器内部执行 top 命令查看,定位到占用CPU高的进程ID,使用 top -Hp <进程ID> 定位到占用CPU高的线程ID。
- 使用 jstack <进程ID> > jstack.txt 将进程的线程栈打印输出。
- 退出容器, 使用 docker cp <容器ID>:/usr/local/tomcat/jstack.txt ./ 命令将jstack文件复制到宿主机,便于查看。获取到jstack信息后,赶紧重启服务让服务恢复可用。
5.将2中占用CPU高的线程ID使用 pringf '%x\n' <线程ID> 命令将线程ID转换为十六进制形式。假设线程ID为133,则得到十六进制85。在jstack.txt文件中定位到 nid=0x85的位置,该位置即为占用CPU高线程的执行栈信息。如下图所示,
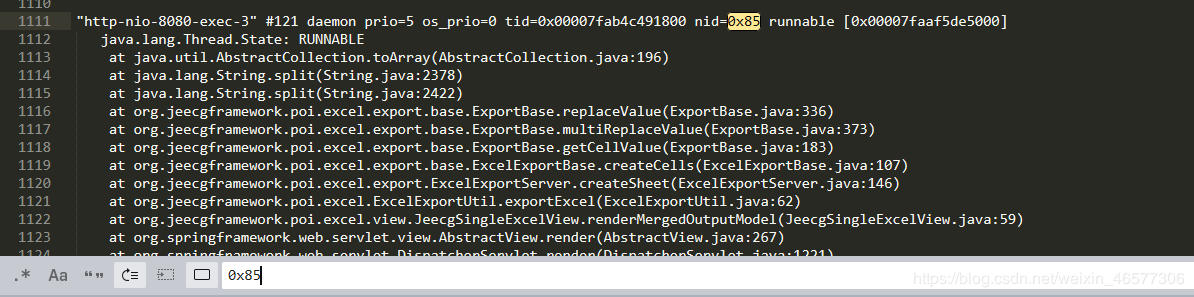
- 与同事确认,该处为使用一个框架的excel导出功能,并且,导出excel时没有分页,没有限制!!!查看SQL查询记录,该导出功能一次导出50w条数据,并且每条数据都需要做转换计算,更为糟糕的是,操作者因为导出时久久没有响应,于是连续点击,几分钟内发起了10多次的导出请求。。。于是,CPU被打满,服务崩溃了,我也崩溃了。。
解决
对于此类耗资源的操作,一定要做好相应的限制。比如可以限制请求量,控制最大分页大小,同时可以限制访问频率,比如同一用户一分钟内最多请求多少次。
再发
服务重启后恢复。到了下午,又一台服务器节点CPU告警,依前面步骤定位到占用CPU高的线程,如下
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007fa114020800 nid=0x10 runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007fa114022000 nid=0x11 runnable使用命令 jstat -gcutil <进程ID> 2000 10 查看GC情况,如图
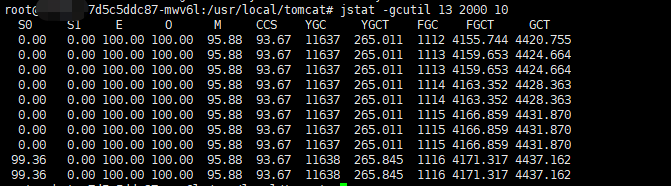
发现Full GC次数达到1000多次,且还在不断增长,同时Eden区,Old区已经被占满(也可使用`jmap -heap
<进程ID>`查看堆内存各区的占用情况),使用jmap将内存使用情况dump出来,
jmap -dump:format=b,file=./jmap.dump 13退出容器,使用 docker cp <容器ID>:/usr/local/tomcat/jmap.dump ./
将dump文件复制到宿主机目录,下载到本地,使用 MemoryAnalyzer(下载地址:www.eclipse.org/mat/downloa…
)打开,如图
如果dump文件比较大,需要增大MemoryAnalyzer.ini配置文件中的-Xmx值
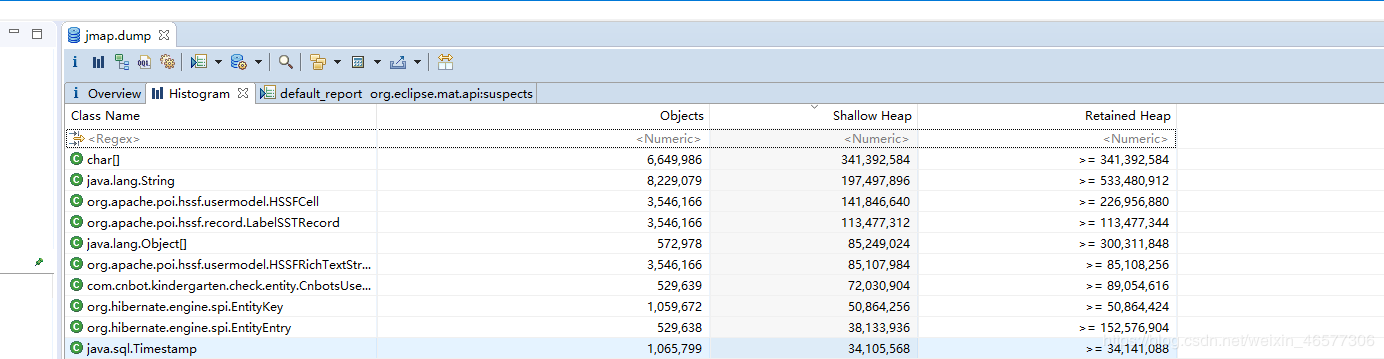
发现占用内存最多的是char[], String对象,通过右键可以查看引用对象,但点开貌似也看不出所以然来,进入内存泄露报告页面,如图
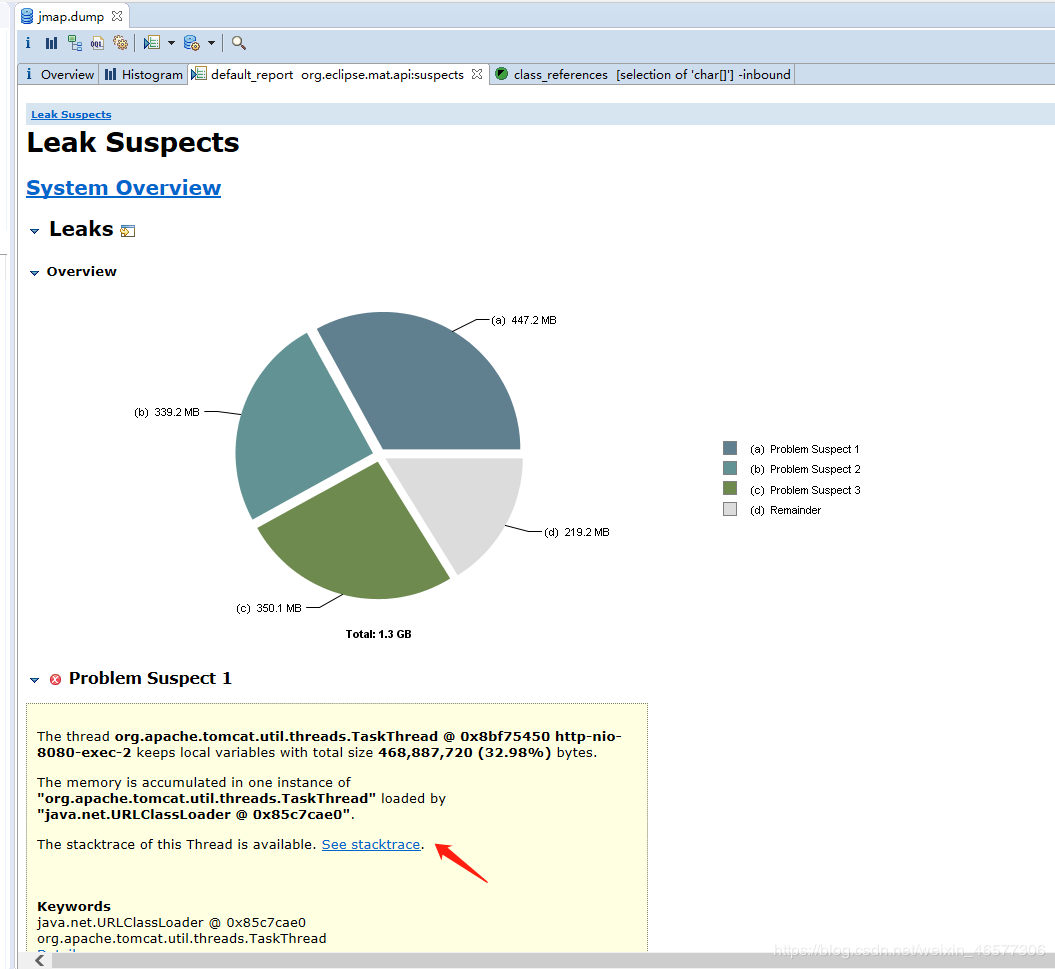
该页面统计了堆内存的占用情况,并且给出疑似泄露点,在上图中点开“see stacktrace”链接,进入线程栈页面,
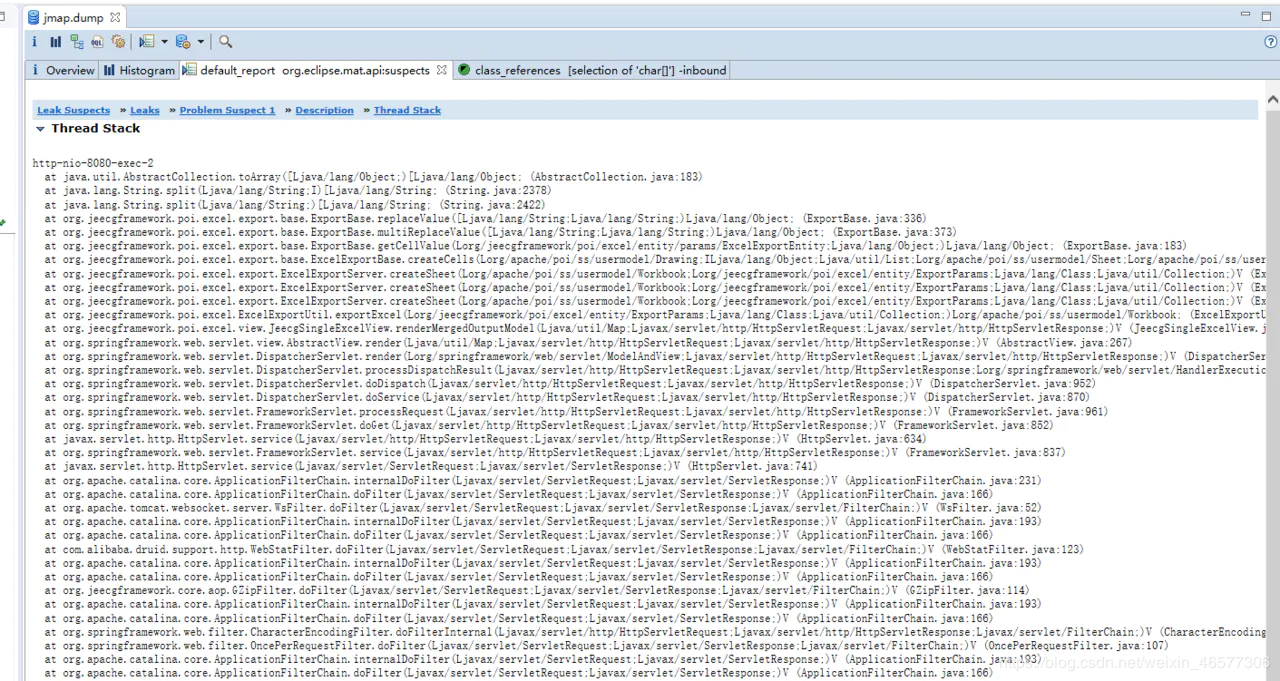
似曾熟悉的画面,还是跟excel导出有关,数据太多,导致内存溢出。。。于是GC频繁,于是CPU爆了。根源还是同一个。
总结
本文以处理一次线上服务CPU 100%的实战过程示例了在遇到Java服务造成服务器CPU消耗过高或内存溢出的一般处理方法,希望对大家定位线上类似问题提供参考。同时,开发实现功能时需要考虑的更深远一些,不能停留在解决当前的场景,需要考虑数据量不断增大时,你的实现是否还能适用。俗话说,初级程序员解决当前问题,中级程序员解决两年后的问题,高级程序员解决五年后的问题,_。
原文链接:https://www.cnblogs.com/MonsterJ/p/13301217.html