缩小邮编操作的差距
尽管Java没有提供zip操作,您也不需要30条额外的代码来实现它,也不需要第三方库。只需通过现有的Stream API组成一个zipline。
Abstract 从第8版开始,Java通过其Stream接口提供了一种简单的方法来查询元素序列,该接口提供了一些开箱即用的操作。这组操作非常通用,但是可以预期,它并不涵盖程序员可能需要的所有操作。其中一种操作是zip,正如我们在Stackoverfow中访问量最大的Java流文章之一所述:使用带有lambda的JDK8(java.util.stream.Streams.zip)压缩流。即使7年后,我们现在仍在Java 14版本上,并且Streams还没有zip操作。
但是,从提供的所有解决方法到没有zip,所有这些方法至少都具有以下缺点之一:
1.详细
2.不流利;
3.表现不佳;
4.第三方库的依赖性。
实际上,基于Java的Stream可扩展性,投票最多的答案不仅需要35行代码来实现辅助zip()方法(1. Verbosity),而且还中断了流水线的流畅链接(2. Non-fluent)而且,它还远不是性能最高的替代方案(3.表现不佳)。
在这里,我们分析了Java流扩展性的其他替代方法(第2.1节),即使用第三方库来抑制zip的缺失(例如2.2节中的Guava或 Protonpack)或用另一种类型的Java完全替换Stream。序列(如2.3节中的jOOλ,Jayield,StreamEx和Vavr)。并且,在比较中,我们还包括第四个替代方案,称为zipline(在2.4节中),该方案将map()操作与使用辅助迭代器结合在一起以实现所需的zip处理。
接下来,我们会给所有进一步的细节,这些解决方案,并以基准江铃控股有限公司的支持查询内置了性能分析every()和find()(中提到的#1问题通过)横穿两个序列zip() 的每个替代提供的操作。为了获得公正的结果,我们还开发了另一个基准,该基准使用实际的数据源(即Last.fm Web API)测试更复杂的查询。
在所有可能的情况下,没有最好的解决方案,因此在本文中,我们总结了每种方法针对上述四个缺点的行为。简而言之,从我们的结果中,我们可以观察到,关于投票最多的答案所获得的优势要小于其他任何替代方案,并且还有其他可行的选择更适合于每种开发环境的约束条件。
1.简介 Zip,也称为卷积,是一种将序列元组映射为元组序列的函数。作为练习,让我们想象一下Stream支持zip,并且我们有一个带有歌曲名称的流,而另一个带有相同歌曲的艺术家的名称的流,我们可以使用zip将它们配对,如下所示:
Stream<String> songs = Stream.of("505", "Amsterdam", "Mural");
Stream<String> artists = Stream.of("Arctic Monkeys", "Nothing But Thieves", "Lupe Fiasco");
songs.zip(artists, (song, artist) -> String.format("%s by %s", song, artist))
.forEach(song -> System.out.println(song));
我们的控制台输出为:
505 by Arctic Monkeys
Amsterdam by Nothing But Thieves
Mural by Lupe FiascoZip是Java不开箱即用地支持的操作之一,但这并不意味着我们不能自己实现它。Java还为我们提供了一种通过实现流源在流管道中引入新的自定义操作的方法。
在本文中,我们将提供一些有关如何在Java中实现zip操作的替代方法。我们将比较它们的功能,并根据上面列出的四项开销对其进行测量,以及与Java Stream的兼容性。之后,我们将使用提出的不同替代方案对不同的查询进行基准测试,并查看它们之间的相互关系。
2. Java Zip替代品 有多种方法可以在Java中设置zip操作,即:
- Java的流可扩展性
- 插入第三方实用程序,例如
Streams(Guava)或StreamUtils(Protonpack) - 用其他类型的序列替换Stream,例如
Seq(jOOλ),Query(Jayield),StreamEx(StreamEx)或Stream(Vavr) - 结合现有的J
ava Stream操作-zipline
2.1 Java的流可扩展性 为了程序和使用自定义流操作,Java提供了StreamSupport类,它提供的方法来创建流出来的Spliterator。因此,考虑到zip操作,我们实现了siki提出的解决方案。
简而言之,此解决方案从流源获取迭代器,并将其项组合为新的项,然后将其Iterator进一步转换为a Spliterator,然后转换为new Stream,如以下草图所示:

因此,迭代器从的组合产生elements和other根据以下表中:
Iterator<T> zippedIterator = new Iterator<T>() {
@Override
public boolean hasNext() {
return elements.hasNext() && other.hasNext();
}
@Override
public T next() {
return zipper.apply(elements.next(), other.next());
}
};
由此zippedIterator,siki的提议Stream从以下组成获得了最终结论:
StreamSupport.stream(Spliterators.spliterator(zippedIterator, ...)...)
回到歌曲的示例,这是我们将如何使用新定义的zip操作的方法:
zip(
getSongs(),
getArtists(),
(song, artist) -> String.format("%s by %s", song, artist)
).forEach(song -> System.out.println(song));
这是Java当前提供的方法。它具有不需要任何其他库的优点,但是另一方面,它非常冗长,正如siki提出的zip方法的定义所看到的那样,该方法需要将近35行代码。此外,当我们使用新的自定义操作时,我们丢失了流操作提供的流畅管道,而是将流嵌套在方法中。尽管生成的管道由getSongs() + getArtists() --> zip ---> forEach,但是方法调用以不同的顺序编写,其中zip()调用出现在头部。
2.2。与第三方实用程序类交错
我们可能会使用第三方实用程序库,而不是开发自己的zip函数,而是利用它们的操作与Stream的方法调用交错在一起。Protonpack的StreamUtils类提供了这种方法,而Guava的Streams提供了这种方法。关于使用上一节新的zip操作的示例,我们可以zip使用Streams.zip(...)或StreamUtils.zip(...)取决于我们使用的是Guava还是Protonpack来替换对自己的实现的调用。的实用程序类。这种方法不那么冗长,因为我们不必自己定义zip操作,但是如果要使用它,就必须向项目添加新的依赖项。
2.3用其他顺序替换流
一个流具有相同的属性,任何其他序列的管道。马丁·福勒(Martin Fowler)在其2015年的著名文章“ Collection Pipeline ”中已经描述了这种模式。序列的流水线由一个源,零个或多个中间操作和一个终端操作组成。源可以是任何提供对元素序列的访问的东西,例如数组或生成器函数。中间操作将序列转换为其他序列,例如过滤元素(e.g. filter(Predicate<T>)),通过映射函数(map(Function<T,R>))转换元素,截断可访问元素的数量(例如limit(int)),或使用许多其他流生成操作之一。终端操作也称为价值或产生副作用的操作,要求操作元素,从而消耗了序列。这些操作包括聚合(例如reduce()或)collect(),搜索(例如findFirst()或anyMatch())和迭代(使用)forEach()。
随着中说有一些替代Java的流的执行序列,如StreamEx,查询由Jayield,SEQ通过jOOλ或流通过Vavr。现在,让我们来看看如何我们的例子来自“ Java的流可扩展性”,使用的行为序列由jOOλ:
Seq<String> songs = Seq.of("505", "Amsterdam", "Mural");
Seq<String> artists = Seq.of("Arctic Monkeys", "Nothing But Thieves", "Lupe Fiasco");
songs
.zip(artists)
.map((tuple) -> String.format("%s by %s", tuple.v1, tuple.v2))
.forEach(song -> System.out.println(song));
Stream不管序列类型的变化如何,例如SeqjOOλ库,用第三方实现代替都会导致与本示例中介绍的用法类似。这种方法在很多方面类似于“ 2.2与第三方实用程序的交错”中介绍的方法,其另外的好处是可以保持流畅的操作流程。此处的方法的调用,如zip(),map()和foreach()通过方法调用的序列,其中每个呼叫作用于先前的呼叫的结果被链接。
2.4合并现有的Java Stream操作-zipline 在压缩两个序列时,既不需要使用第三方实用程序库也不中断流畅的操作流水线的一种方法就是将流操作映射与老式的迭代器简单地组合在一起。
考虑到我们要合并两个序列:elements和和other(的实例Stream),那么可以通过以下本机操作的组合来实现我们的目标(表示为结果zipline)Stream:
var o = other.iterator(); var zipline = elements.map(e -> Pair(e, o.next())));
关于使用歌曲压缩艺术家的用例,然后使用zipline方法,我们可以在以下清单中实现我们的目标:
Iterator<String> artists = getArtists().iterator();
getSongs()
.map(song -> String.format("%s by %s", song, artists.next()))
.forEach(song -> System.out.println(song));
Zipline具有使用第三方序列替代方法的流利性优点,但具有不需要进一步依赖的额外好处。此外,zipline 简洁明了,避免了实现custom的所有冗长细节Spliterator。
3.功能比较 在本节中,我们提供一个表格,该表格概述了有关本文开头描述的缺点的各种方法以及它们与Java Stream的兼容性。关于性能,我们包括四个基准测试结果,这些结果给出了相对于Java的Stream可扩展性(原始有关zip的Stackoverflow问题的公认答案)所观察到的性能提高的速度。
这四个结果处理四个不同的查询管道,即 关于zip的Stackoverflow问题中提到的every() 和 find()操作,以及两个处理来自Last.fm Web API的数据的更复杂的管道,其中distinct() 一个filter()在zip上包含a ,另一个在a上。对于后两个结果,我们以百分比表示加速。
我们将在“ 4.基准测试的域模型和查询”一节中更详细地说明这些操作。该表根据“性能评估”部分的性能结果表中使用的相同颜色,按照第二部分-Java Zip Alternatives中提出的4个选择,对不同的方法进行了分组。
| Verboseless | 3r Party Free | Fluent | Stream Compatible | every | find | distinct | filter | |
|---|---|---|---|---|---|---|---|---|
| Stream ext. | x | ✔ | x | NA | ||||
| Guava | ✔ | x | x | x | -1.1 | 1.1 | -1% | 2% |
| Protonpack | ✔ | x | x | x | -1.1 | 1.0 | -3% | 2% |
| StreamEx | ✔ | x | ✔ | ✔ | 1.0 | 1.0 | -11% | -6% |
| Jayield | ✔ | x | ✔ | toStream() | 3.4 | 2.9 | 11% | 37% |
| jOOλ | ✔ | x | ✔ | ✔ * | -1.3 | -1.2 | -23% | -16% |
| Vavr | ✔ | x | ✔ | toJavaStream() | -6.9 | -5.0 | -31% | -53% |
| Zipline | ✔ | ✔ | ✔ | NA | 1.5 | 1.1 | 8% | 3% |
(*尽管与Seq兼容,Stream但不支持并行处理。)
比较这些方法,我们可以看到,Verbosity唯一产生的一种是“ 2.1 Java的流可扩展性”提供的,而所有其他方法都是Verboseless的。但是,所有这些替代方案都依赖于第三方库,但基于现有Java Stream API构建的Zipline习惯用语除外。
另一方面,用Stream其他Sequence实现替换类型,甚至使用Zipline惯用语,我们都可以保持流畅的管道。
性能最高的方法是Jayield和Zipline的Query,我们将在性能基准测试结果中进一步确认。尽管jOOλ和StreamEx的性能比竞争对手差,但它们提供了全套查询操作,并且与JavaStream类型完全兼容。最后,尽管Vavr在这些Github存储库中最受欢迎,但与分析功能和基准测试的替代方案相比,它没有任何优势。
4.基准测试的领域模型和查询 为了测试每种方法的性能,我们决定设计一些查询并将它们作为基准。
4.1每个都找到 考虑到最初的Stackoverflow问题。我们决定对这两个操作也进行基准测试,因为它们是artella提出的问题的重点。
Every是一个基于用户定义的谓词的操作,用于测试序列中的所有元素在相应位置之间是否匹配。因此,例如,如果我们有:
Stream seq1 = Stream.of("505", "Amsterdam", "Mural");
Stream seq2 = Stream.of("505", "Amsterdam", "Mural");
Stream seq3 = Stream.of("Mural", "Amsterdam", "505");
BiPredicate pred = (s1, s2) -> s1.equals(s2);
然后:
every(seq1, seq2, pred); // returns true
every(seq1, seq3, pred); // returns false
为了every返回true,每个序列的每个元素都必须在同一索引中匹配。该every功能可以通过zip-allMatch操作的管道来实现,例如:
seq1.zip(seq2, pred::test).allMatch(Boolean.TRUE::equals);
在find两个序列之间是一个操作,即,基于用户定义的谓词,发现两个元件相匹配的,在该过程返回它们中的一个。因此,如果我们有:
Stream seq1 = Stream.of("505", "Amsterdam", "Mural");
Stream seq2 = Stream.of("400", "Amsterdam", "Stricken");
Stream seq3 = Stream.of("Amsterdam", "505", "Stricken");
BiPredicate pred = (s1, s2) -> s1.equals(s2);
然后:
find(seq1, seq2, pred); // returns "Amsterdam"
find(seq1, seq3, pred); // returns null
find(seq2, seq3, pred); // returns "Stricken"
为了find返回一个元素,每个序列的两个元素必须在同一索引中匹配。这是find在a的支持下实现的样子zip:
zip(seq1, seq2, (t1, t2) -> predicate.test(t1, t2) ? t1 : null)
.filter(Objects::nonNull)
.findFirst()
.orElse(null);
就像我们看到的那样,find这类似于every两个zip序列都使用谓词,并且如果我们在序列的最后一个元素上有匹配项,则它会贯穿整个序列every。考虑到这一点,我们认为find使用具有许多元素的序列进行基准测试并仅在最后一个元素中进行匹配不会为该分析增加太多价值。因此,我们设计了一个基准,在该基准中,匹配索引从第一个索引到最后一个索引都将有所不同,并且仅分析了1000个元素的序列。另一方面,我们every以10万个元素的序列为基准。
4.2。Artists and Tracks 寻找与现实的数据更复杂的管道,我们采取公开可用的Web的API,即REST国家和Last.fm。我们从REST国家/地区检索了250个国家/地区的列表,然后使用它们查询Last.fm API,以按国家/地区检索顶级艺术家和顶级曲目,因此每个国家总共有7500个条目。
我们的领域模型可以归纳为以下这些类别的定义:国家/地区,语言,艺术家和曲目。

我们两个查询都来自相同的依据。我们首先查询所有国家/地区,然后过滤掉不会说英语的国家/地区,然后从中检索出两个序列:一个与国家/地区配对,另一个是与国家/地区最重要的曲目,以及与之相关的艺术家。
Sequence<Pair<Country, Sequence<Track>>> getTracks() {
return getCountries()
.filter(this::isNonEnglishSpeaking)
.map(country -> Pair.with(country, getTracksForCountry(country)));
}
Sequence<Pair<Country, Sequence<Artist>>> getArtists() {
return getCountries()
.filter(this::isNonEnglishSpeaking)
.map(country -> Pair.with(country, getArtistsForCountry(country)));
}
从这里开始,我们的查询会有所不同,因此我们将分别进行解释。
不同国家的杰出艺术家和最佳曲目 此查询包括将上述两个序列与国家/地区一起压缩到一个三重奏中,它是最高艺术家,也是最高曲目,然后按艺术家选择不同的条目。
Sequence<Trio<Country,Artist,Track>> zipTopArtistAndTrackByCountry() {
return getArtists()
.zip(getTracks())
.map(pair -> Trio.with(
pair.first().country,
pair.first().artists.first(),
pair.second().tracks.first()
))
.distinctByKey(Trio::getArtist);
}
在一国前十名中的艺术家,同时也在该国前十名中拥有曲目。 与上一个查询一样,此查询首先压缩两个序列,但是这次,对于每个国家/地区,我们采用排名前十位的艺术家和排名前十位的曲目艺术家的名字,然后将其压缩为Trio。之后,将根据排名前十位的曲目艺术家姓名中的存在来筛选排名前十位的艺术家,并返回与“国家/地区”对和由此产生的音序。
Sequence<Pair<Country,Sequence<Artist>>> artistsInTopTenWithTopTenTracksByCountry() {
return getArtists()
.zip(getTracks())
.map(pair -> Trio.with(
pair.first().country,
pair.first().artists.limit(10),
pair.second().tracks.limit(10)
.map(Track::getArtist)
.map(Artist::getName)
)).map(trio -> Pair.with(
trio.country,
trio.artists.filter(artist -> trio.tracksArtists.contains(artist.name))
));
}
源代码 对于这些查询的实际实现,您可以随时检查我们的Github存储库。您会发现其中一些方法和属性不存在(first(),second(),国家(地区)等),但是为了使概念更清晰易懂,我们在本文中使用了这些属性。
5.绩效评估
为了避免在基准测试执行期间进行IO操作,我们先前已将所有数据收集到资源文件中,并将所有数据加载到基准测试引导程序中的内存中数据结构中。因此,流源是从内存中执行的,并且避免了任何IO。
为了比较上述多种方法的性能,我们使用jmh对上述两个查询进行了基准测试。我们在本地机器以及GitHub中都通过GitHub动作运行了这些基准测试,这些动作通过本地收集的性能测试呈现了一致的行为和结果。
我们的本地计算机具有以下规格:
Microsoft Windows 10 Home
10.0.18363 N/A Build 18363
Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz, 2801 Mhz, 4 Core(s), 8 Logical Processor(s)
JDK 11.0.6, Java HotSpot(TM) 64-Bit Server VM, 11.0.6+8-LTS基准测试在我们的本地计算机和github上都运行,并将以下选项传递给jmh:
-i 10 -wi 10 -f 3 -r 15 -w 20 --jvmArgs "-Xms2G -Xmx2G"
这些选项对应于以下配置:
-i 10 -运行10次测量迭代。
-wi 10-运行10个热身迭代。
-f 3 -分叉每个基准测试3次。
-r 15 -每次测量迭代至少要花费15秒。
-w 20 -每次预热迭代至少要花费20秒。
--jvmArgs "-Xms2G -Xmx2G"-将初始和最大Java堆大小设置为2 Gb。
本地机器结果
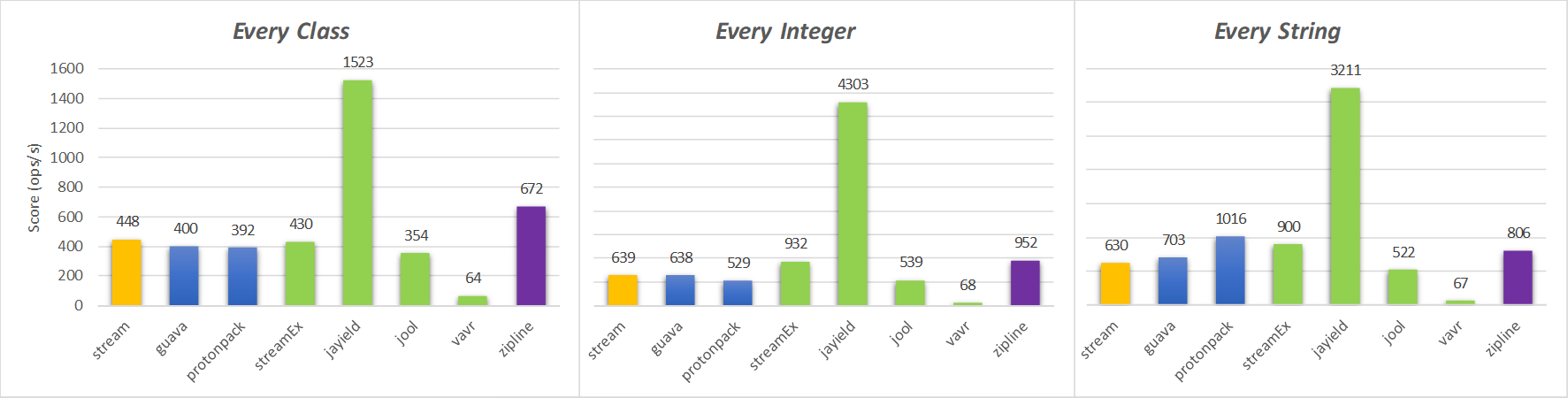
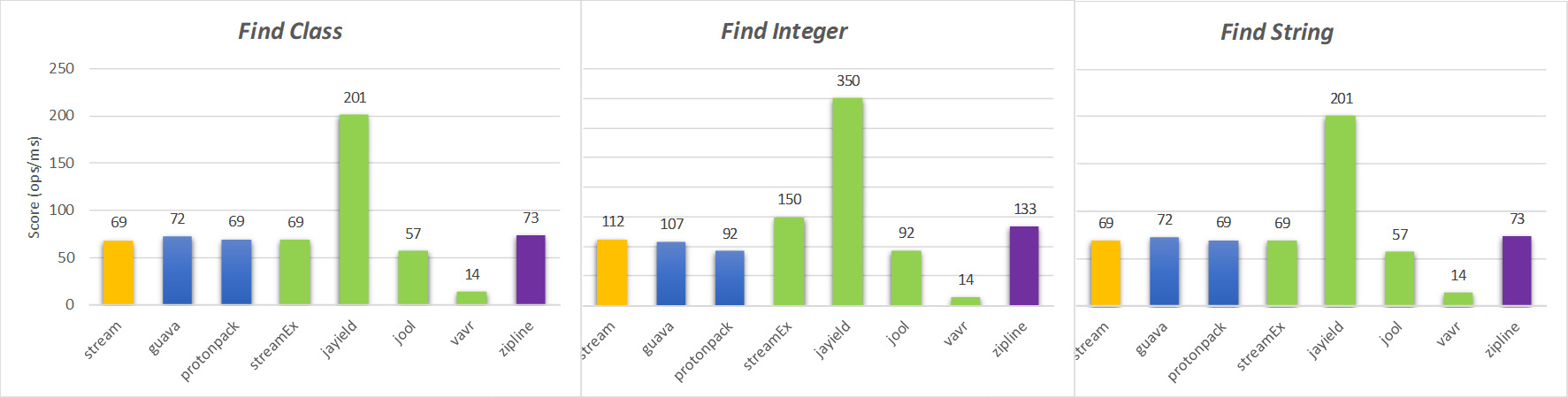
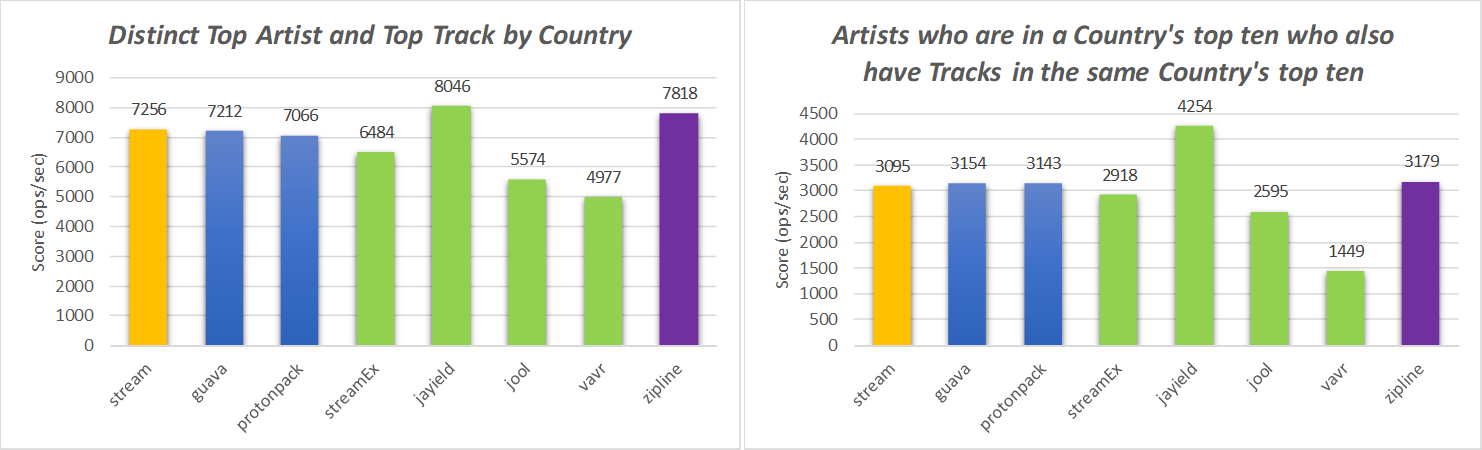
从这些图表中显示的结果可以看出,基于公认的Stackoverflow答案(标记为“流”)的解决方案并不是最有效的选择。此外,除了前面几节中已经提到的性能以外,它还有其他缺点。
第三方库Jayield的使用优于所有其他两个操作选择,every()并且find() 在StackOverflow有关压缩Java流的问题中,原始海报中提到了第三方库。尽管Jayield在Artists and Tracks基准测试中也是表现最出色的,但在比赛中却表现出微妙的加速。
但是,如果不能将依赖项添加到诸如Jayield之类的辅助库中,则zipline将是最佳选择。map()与实施基于zip的链相比,使用zipline惯用语表示的链与辅助迭代器的组合,比实现一个Spliterator基于zip的链更为简单和有效。此外,它们zip()不能在流管道中流畅地链接,而zipline保持了查询管道的流畅本质。最后,在分析的基准测试中,zipline是性能第二强的解决方案。
StreamEx还是一个不错的选择,它提供了一系列开箱即用的操作来构建各种各样的查询管道。它具有与Java流类完全兼容的巨大优势。但是,与Jayield相比,它的性能较差。
jOOλ和Vavr 是具有StreamEx相同目标的其他选项,但是在zip基准测试中无法与其他替代产品在性能上竞争。
最后,Guava和Protonpack选项呈现出与Spliterator基于zip的相似的性能。这是可以预期的,因为这些解决方案也基于Spliterator接口的实现,因此会产生相同的开销。因此,这些库的唯一优点是避免zip()了从头开始实现的冗长性。但是,在流水线流畅性和性能损失方面,两者都具有相同的缺点。
6。结论 Java Streams是软件工程的杰作,它允许顺序或并行地查询和遍历序列。但是,它不包含也不包含每个用例所需的每个操作。就是这种情况zip()。
在本文中,我们重点介绍了有关选择一种替代方法来抑制zip()Java流中不存在该操作的其他问题。我们认为,关于投票最受认可的答案不是最佳选择,它会带来3个缺点:冗长,流水线流畅性丧失和性能不佳。
我们还证明,基于第三方库(例如Guava和Protonpack)的使用,第三票获得了最多的投票,也产生了类似的开销,而不是最佳选择。
我们在分析中引入了其他选项,即zipline习惯用语和Jayield库,并且我们还基于实际数据源构建了zip基准测试,以公平地比较所有替代方案。该基准可在Github上使用,结果可在Github Actions上公开看到。
我们希望所有这些结果和评估的特性可以作为基础,以帮助开发人员做出选择以抑制zip操作的缺失。
原文链接:http://codingdict.com