最佳的Java数据计算层工具
在大多数情况下,结构化数据是使用SQL在数据库内计算的。在数据库不存在或不可用的其他一些情况下,Java程序员需要使用Java执行计算。但是,硬编码涉及繁重的工作量。一个更方便的替代方法是Java数据计算层工具(包括库函数)。该工具计算数据并返回结果集。在这里,我们检查了几种Java数据计算层工具的结构化数据计算能力。
1.用于文件的SQL引擎
这种类型的工具使用诸如CSV和XLS之类的文件(例如物理数据库表),并向上提供JDBC接口,以允许程序员计算SQL语句中的表。有许多这种类型的产品,例如CSVJDBC,XLSJDBC,CDATA Excel JDBC和xlSQL,但是还没有一个成熟的产品可以方便地使用。如果我们必须选择其中之一,则CSVJDBC是最成熟的。
CSVJDBC是一个免费的开源Java类库,它自然是易于集成的。用户只需要下载一个jar,即可通过JDBC接口将其与Java程序集成。以下是制表符分隔的文本文件d:\ data \ Orders.txt的一部分:
OrderID Client SellerId Amount OrderDate
26 TAS 1 2142.4 2009-08-05
33 DSGC 1 613.2 2009-08-14
84 GC 1 88.5 2009-10-16
133 HU 1 1419.8 2010-12-12
…
以下代码块读取文件的所有记录,并在控制台中将它们打印出来:
package csvjdbctest;
import java.sql.*;
import org.relique.jdbc.csv.CsvDriver;
import java.util.Properties;
public class Test1 {
public static void main(String[] args) throws Exception {
Class.forName("org.relique.jdbc.csv.CsvDriver");
// Create a connection to directory given as first command line
String url = "jdbc:relique:csv:" + "D:\\data" + "?" + "separator=\t" + "&" + "fileExtension=.txt";
Properties props = new Properties();
// Can only be queried after specifying the type of column
props.put("columnTypes", "Int,String,Int,Double,Date");
Connection conn = DriverManager.getConnection(url,props);
// Create a Statement object to execute the query with.
Statement stmt = conn.createStatement();
//SQL: Conditional query
ResultSet results = stmt.executeQuery("SELECT * FROM Orders");
// Dump out the results to a CSV file/console output with the same format
CsvDriver.writeToCsv(results, System.out, true);
// Clean up
conn.close();
}
}
Java类库对热部署有很好的支持。这是因为它在SQL中实现了计算,并且可以方便地将SQL查询与Java代码分开。用户可以直接修改SQL语句,而无需编译或重新启动应用程序。
尽管CSVJDBC在Java集成和热部署方面非常出色,但它们不是Java数据计算层工具的核心功能。结构化数据计算能力是该工具的核心,但是JDBC驱动程序的性能很差。
CSVJDBC仅支持有限数量的基本计算,包括条件查询,排序和分组以及聚合。
// SQL: Conditional query
ResultSet results = stmt.executeQuery("SELECT * FROM Orders where Amount>1000 and Amount<=3000 and Client like'%S%' ");
// SQL: order by
results = stmt.executeQuery("SELECT * FROM Orders order by Client,Amount desc");
// SQL: group by
results = stmt.executeQuery("SELECT year(Orderdate) y,sum(Amount) s FROM Orders group by year(Orderdate)");面向集合的操作,子查询和联接操作也是基本计算的一部分,但不支持所有这些。即使是几个受支持的程序也有很多问题。例如,CSVJDBC要求将所有文件数据都加载到内存中以进行排序,分组和聚合操作,因此,如果文件大小不太大会更好。
SQL语句不支持调试并且性能很差。CSVJDBCA仅支持CSV文件。其他数据格式,数据库表,Excel文件和JSON数据应转换为CSV文件以进行处理。由于需要硬编码或第三方工具,因此转换成本低廉。
2. dataFrame通用函数库
这种工具旨在通过提供类似于dataFrame的通用数据类型,向下对接各种数据源以及向上提供功能接口来模拟Python Pandas。桌锯,细木工,Morpheus,Datavec,Paleo,Guava等许多其他类型都属于此类型。由于Pandas是成功的先驱,这种Java数据计算层工具无法吸引许多追随者,因此其开发水平普遍较低。Tablesaw(最新版本为0.38.2)是其中最发达的一种。
作为一个免费的开放源代码Java类库,Tablesaw只需要集成核心jar和相关程序包即可。它生成的基本代码也很简单。例如,要读取和打印Orders.txt的所有记录,我们具有以下代码:
package tablesawTest;
import tech.tablesaw.api.Table;
import tech.tablesaw.io.csv.CsvReadOptions;
public class TableTest {
public static void main(String[] args) throws Exception{
CsvReadOptions options_Orders = CsvReadOptions.builder("D:\\data\\Orders.txt").separator('\t').build();
Table Orders = Table.read().usingOptions(options_Orders);
System.out.println(orders.print());
}
}
除CSV文件外,Tablsaw还支持其他类型的源,包括RDBMS,Excel,JSON和HTML。基本上可以满足日常分析工作。通过支持一组功能(例如断点,步进,进入和退出),这些功能计算带来了令人满意的调试体验,同时通过要求对算法的任何更改进行重新修改而降低了热部署性能。
结构化数据计算始终是我们关注的重点。以下是一些基本计算:
// Conditional query
Table query= Orders.where(
Orders.stringColumn("Client").containsString("S").and(
Orders.doubleColumn("Amount").isGreaterThan(1000).and(
Orders.doubleColumn("Amount").isLessThanOrEqualTo(3000)
)
)
);
// Sorting
Table sort = Orders.sortOn("Client", "-Amount");
//Grouping & aggregation
Table summary = Orders.summarize("Amount", sum).by(t1.dateColumn("OrderDate").year());
// Joins
CsvReadOptions options_Employees = CsvReadOptions.builder("D:\\data\\Employees.txt").separator('\t').build();
Table Employees = Table.read().usingOptions(options_Employees);
Table joined = Orders.joinOn("SellerId").inner(Employees,true,"EId");
joined.retainColumns("OrderID","Client","SellerId","Amount","OrderDate","Name","Gender","Dept");
对于仅需要考虑几个因素的排序,分组和聚合操作之类的计算,Tablesaw和SQL之间的差距非常小。如果像条件查询和联接操作这样的计算涉及很多因素,Tablesaw生成的代码将比SQL复杂得多。原因是Java并非本质上用于结构化数据计算,而必须以与SQL相同的计算能力来交换复杂的代码。幸运的是,高级语言支持lambda语法,从而能够生成相对直观的代码(尽管不如SQL直观)。条件查询可以重写如下:
Table query2=Orders.where(
and(x->x.stringColumn("Client").containsString("S"),
and(
x -> x.doubleColumn("Amount").isGreaterThan(1000),
x -> x.doubleColumn("Amount").isLessThanOrEqualTo(3000)
)
)
);
3.轻量级数据库
轻量级数据库的特点是体积小,易于部署且易于集成。轻量级数据库的典型产品包括SQLite,Derby和HSQLDB。让我们特别看一下SQLite。
SQLite是免费和开源的。只需一个jar即可进行集成和部署。它不是独立系统,通常通过API接口在Java之类的主机应用程序中运行。当它在外部存储磁盘上运行时,它支持相对较大的数据量。当它在内存中运行时,它的性能更好,但支持的数据量较小。SQLite遵守JDBC标准。例如,要打印出外部数据库exl中的orders表的所有记录,我们有以下代码:
package sqliteTest;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class Test {
public static void main(String[] args) throws Exception {
Connection connection =DriverManager.getConnection("jdbc:sqlite/data/ex1");
Statement statement = connection.createStatement();
ResultSet results = statement.executeQuery("select * from Orders");
printResult(results);
if(connection != null)connection.close();
}
public static void printResult(ResultSet rs) throws Exception{
int colCount=rs.getMetaData().getColumnCount();
System.out.println();
for(int i=1;i<colCount+1;i++){
System.out.print(rs.getMetaData().getColumnName(i)+"\t");
}
System.out.println();
while(rs.next()){
for (int i=1;i<colCount+1;i++){
System.out.print(rs.getString(i)+"\t");
}
System.out.println();
}
}
}
对SQLite的源数据使用的支持要求很高。无论哪种类型的数据,都必须加载到其中进行计算(某些轻量级数据库可以直接将CSV / Excel文件标识为数据库表)。有两种加载CSV文件Orders.txt的方法。第一种使用Java读取CSV文件,将每一行组成一个插入语句,然后执行这些语句。这需要大量的男女同校。第二是手动。用户下载官方维护工具sqlite3.ext并在命令行上执行以下命令:
sqlite3.exe ex1
.headers on
.separator "\t"
.import D:\\data\\Orders.txt Orders尽管源数据中的丢失点支持可伸缩性,但是数据库软件通过赢得结构化数据计算测试来收回它们。它可以方便地处理所有基本算法,并且性能良好。
// Conditional query
results = statement.executeQuery("SELECT * FROM Orders where Amount>1000 and Amount<=3000 and Client like'%S%' ");
// Sorting
results = statement.executeQuery("SELECT * FROM Orders order by Client,Amount desc");
// Grouping & aggregation
results = statement.executeQuery("SELECT strftime('%Y',Orderdate) y,sum(Amount) s FROM Orders group by strftime('%Y',Orderdate) ");
// Join operation
results = statement.executeQuery("SELECT OrderID,Client,SellerId,Amount,OrderDate,Name,Gender,Dept from Orders inner join Employees on Orders.SellerId=Employees.EId")
简而言之,SQLlite具有SQL引擎的固有特性,即良好的热部署性能和较差的调试经验。
4.专业的结构化数据计算语言
它们旨在计算结构化数据,旨在提高算法的表达效率和执行性能,并支持各种数据源,方便的集成,算法热部署和算法调试。没有很多。Scala,esProc和linq4j是最常用的工具。但是由于linq4j还不够成熟,所以我们只看看另外两个。
Scala被制成通用编程语言。然而,它以其专业的结构化数据计算能力而闻名,它封装了Spark的分布式计算能力以及非框架,与服务无关的本地计算能力。Scala在JVM上运行,因此可以轻松地与Java程序集成。例如,要读入并打印出Orders.txt的所有记录,我们可以首先编写以下TestScala.Scala脚本:
package test
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
object TestScala{
def readCsv():DataFrame={
// Only the jar is needed for a local execution, without configuring or starting Spark
val spark = SparkSession.builder()
.master("local")
.appName("example")
.getOrCreate()
val Orders = spark.read.option("header", "true").option("sep","\t")
// Should auto-parse into the right data type before performing computations
.option("inferSchema", "true")
.csv("D:/data/Orders.txt")
// Should specify the date type for subsequent date handling
.withColumn("OrderDate", col("OrderDate").cast(DateType))
return Orders
}
}
将上面的Scale脚本文件编译成可执行程序(Java类),然后可以从一段Java代码中调用它,如下所示:
package test;
import org.apache.spark.sql.Dataset;
public class HelloJava {
public static void main(String[] args) {
Dataset ds = TestScala.readCsv();
ds.show();
}
}
用于处理基本结构化数据计算的Scala代码非常简单:
//Conditional query
val condtion = Orders.where("Amount>1000 and Amount<=3000 and Client like'%S%' ")
//Sorting
val orderBy = Orders.sort(asc("Client"),desc("Amount"))
//Grouping & aggregation
val groupBy = Orders.groupBy(year(Orders("OrderDate"))).agg(sum("Amount"))
//Join operations
val Employees = spark.read.option("header", "true").option("sep","\t")
.option("inferSchema", "true")
.csv("D:/data/Employees.txt")
val join = Orders.join(Employees,Orders("SellerId")===Employees("EId"),"Inner")
.select("OrderID","Client","SellerId","Amount","OrderDate","Name","Gender","Dept")
// Positions of records are changed after the join, a sorting will keep the order consistent with that of the result set obtained using the other tools
.orderBy("SellerId")
Scala支持在多种数据源上运行相同的代码。它可以被视为Java的改进版,因此它还具有出色的调试体验。但是,作为一种编译语言,Scala很难进行热部署。
有一个工具胜过Scala。esProc是针对结构化数据计算的。集算器提供了一个JDBC接口,可以方便地集成到一个Java程序中。例如,以下是用于读取和打印Orders.txt的所有记录的代码:
package Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class test1 {
public static void main(String[] args)throws Exception {
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection = DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str = "=file(\"D:/data/Orders.txt\").import@t()";
ResultSet result = statement.executeQuery(str);
printResult(result);
if(connection != null){
connection.close();
}
}
public static void printResult(ResultSet rs) throws Exception{
int colCount = rs.getMetaData().getColumnCount();
System.out.println();
for(int i=1;i<colCount+1;i++){
System.out.print(rs.getMetaData().getColumnName(i)+"\t");
}
System.out.println();
while(rs.next()){
for (int i=1;i<colCount+1;i++){
System.out.print(rs.getString(i)+"\t");
}
System.out.println();
}
}
}
用于处理基本结构数据计算的esProc代码简单易懂:
// Conditional query
str = "=T(\"D:/data/Orders.txt\").select(Amount>1000 && Amount<=3000 && like(Client,\"*S*\"))";
// Sorting
str = "=T(\"D:/data/Orders.txt\").sort(Client,-Amount)";
// Grouping & aggregation
str = "=T(\"D:/data/Orders.txt\").groups(year(OrderDate);sum(Amount))";
// Join operations
str = "=join(T(\"D:/data/Orders.txt\"):O,SellerId; T(\"D:/data/Employees.txt\"):E,EId).new(O.OrderID,O.Client,O.SellerId,O.Amount,O.OrderDate,E.Name,E.Gender,E.Dept)";
esProc还为熟练的SQL程序员提供了相应的SQL语法。上面处理分组和聚合的算法可以这样重写:
str="$SELECT year(OrderDate),sum(Amount) from Orders.txt group by year(OrderDate)"esProc算法也可以存储为脚本文件,从而进一步减少了代码耦合。这是一个例子:
Duty.xlsx存储每日值班记录。通常,一个人要连续几个工作日执勤,然后将工作转移到下一个人。基于此表,我们希望依次获取每个人的详细职责数据。下面是数据结构:
源表(Duty.xlsx):
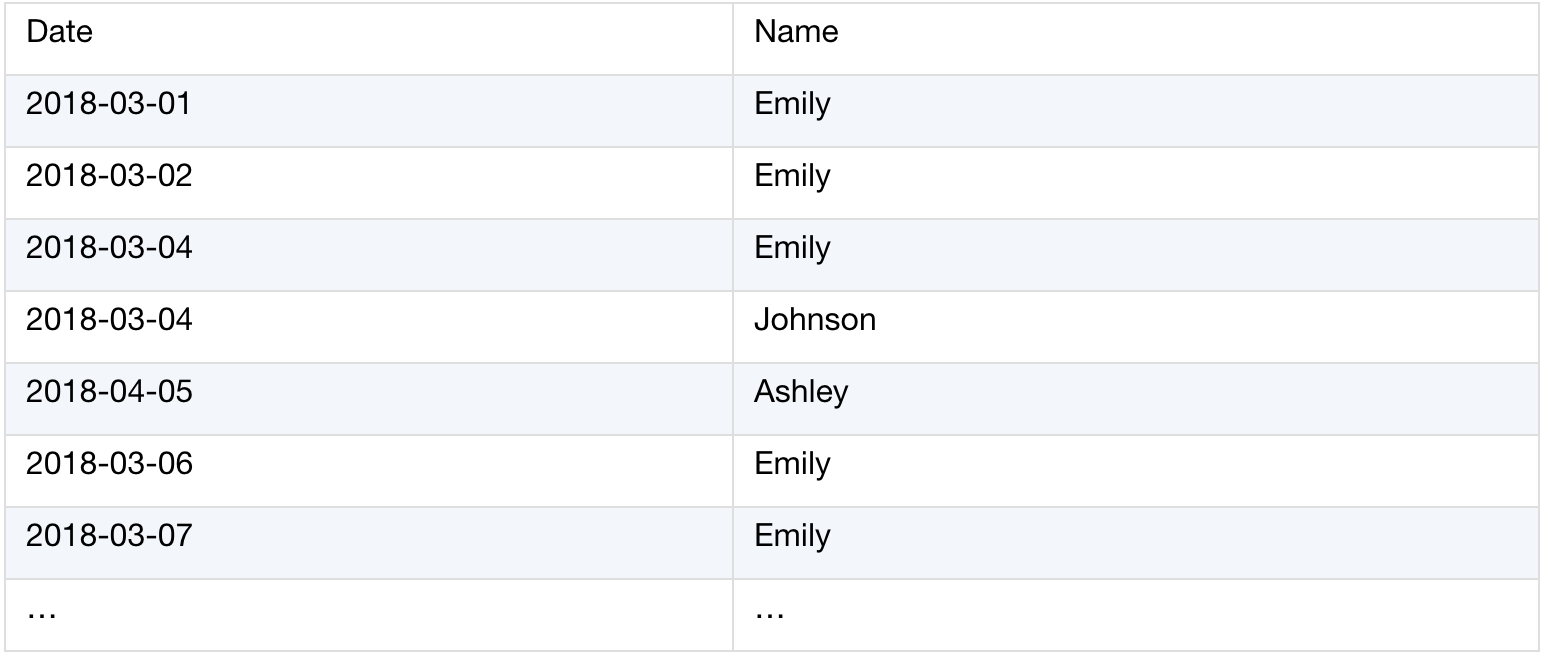
处理结果:
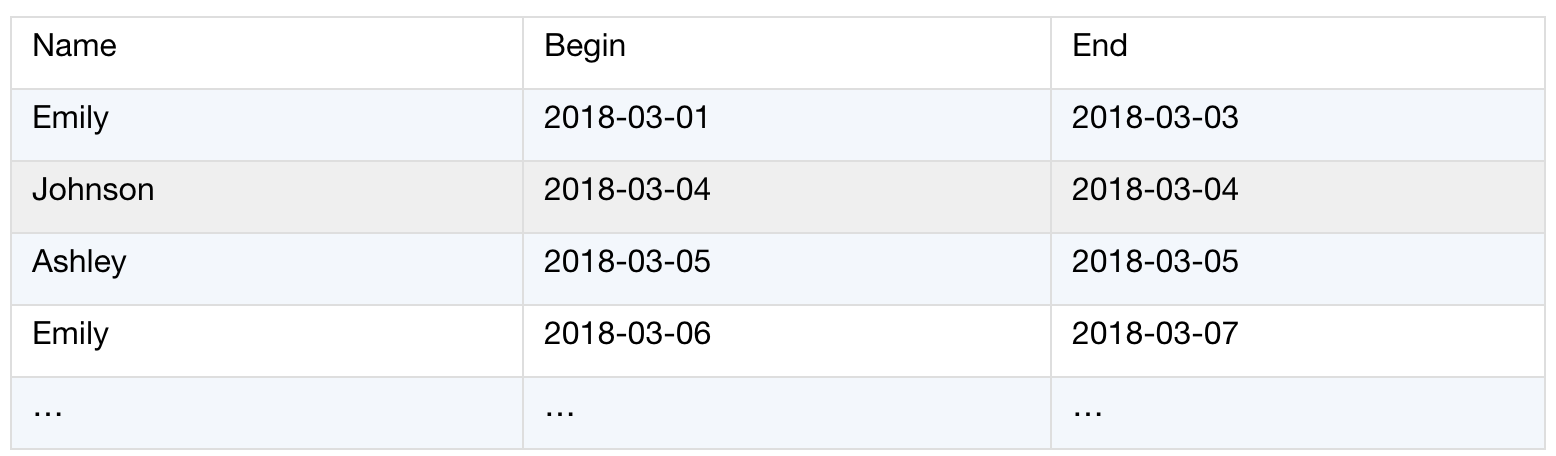
以下esProc脚本文件(con_days.dfx)用于实现上述算法:

然后,可以从下面的Java代码块中调用esProc脚本文件:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection = DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery("call con_days()");
…
尽管上述算法包含复杂的计算逻辑,即使使用Scala或轻量级数据库也很难表达,但esProc易于实现,具有丰富的相关功能和敏捷语法。
将算法放在主应用程序之外还可以使程序员在专用IDE上编辑和调试代码。这有助于实现具有极其复杂逻辑的算法。以运行总计过滤为例:
数据库表销售额存储客户的销售额。主要字段是客户和金额。任务是找到前N个大客户,这些客户的销售额之和至少占总销售额的一半,然后按金额从大到小的顺序对其进行排序。
我们可以使用下面的esProc脚本来实现该算法,然后在Java中调用它:
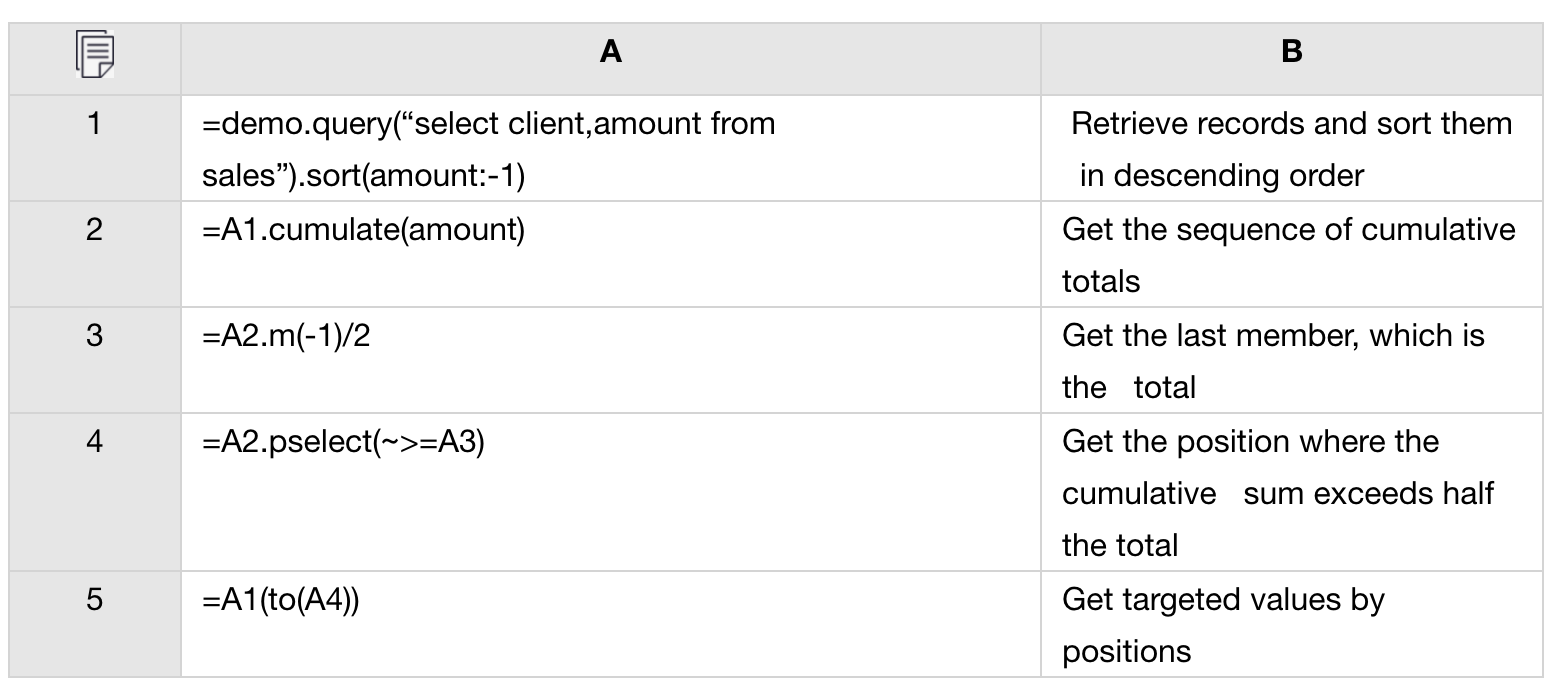
集算器具有最强大的结构化数据计算能力。除此之外,它在许多其他方面也很出色,包括代码调试,数据源支持,大数据计算能力和并行处理支持,这些在其他文章中都有介绍。
原文链接:https://codingdict.com/