超给力,一键生成数据库文档-数据库表结构逆向工程

一、解决什么问题
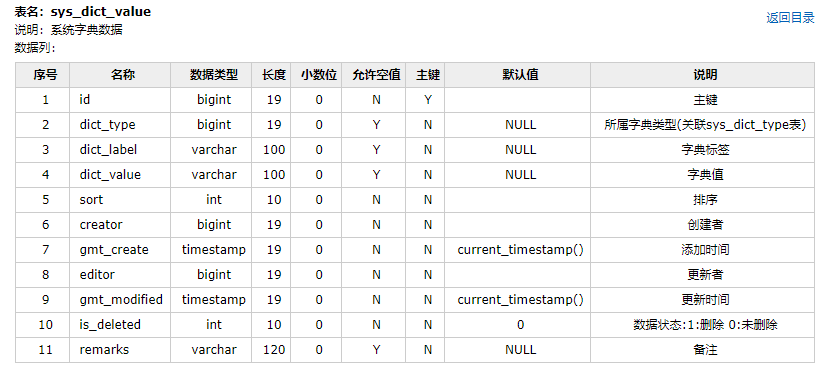
数据库文档是我们在企业项目开发中需要交付的文档,通常需要开发人员去手工编写。编写完成后,数据库发生变更又需要手动的进行修改,从而浪费了大量的人力。并且这种文档并没有什么技术含量,被安排做这个工作的程序员往往自己心里会有抵触情绪,悲观的预期自己在团队的位置,造成离职也是可能的。如下面的这种文档的内容:
笔者最近在github上面发现一个数据库文档生成工具: screw (螺丝钉)。该工具能够通过简单地配置,快速的根据数据库表结构进行逆向工程,将数据库表结构及字段逆向生成为文档。
二、特点
- 简洁、轻量、设计良好
- 多数据库支持:MySQL、MariaDB、TIDB、Oracle、 SqlServer、PostgreSQL、Cache DB
- 多种格式文档: html、word、 markdwon
- 灵活扩展:支持用户自定义模板和展示样式修改(freemarker模板)
三、依赖库探究
mvn中央仓库查看最新版本,将如下的maven坐标引入到Spring Boot项目中去:
<dependency>
<groupId>cn.smallbun.screw</groupId>
<artifactId>screw-core</artifactId>
<version>1.0.3</version>
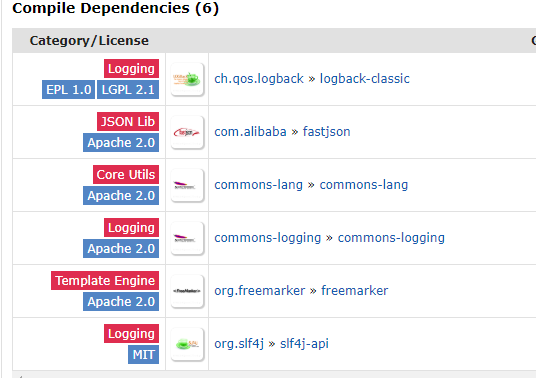
</dependency>从maven仓库的编译依赖中可以看到,screw- core其实现依赖了如下的内容。重点关注freemarker,因为该项目是使用freemarker作为模板生成文档。
除此之外,screw使用了HikariCP作为数据库连接池,所以:
- 你的Spring Boot项目需要引入HikariCP数据库连接池。
- 根据你的数据库类型及版本,引入正确的JDBC驱动
四、开始造作吧
以上的工作都做好之后,我们就可以来配置文档生成参数了。实现文档生成有两种方式,一种是写代码,一种是使用maven 插件。
- 我个人还是比较喜欢使用代码的当时,写一个单元测试用例就可以了,相对独立,使用方式也灵活。
- 如果放在pom.xml的插件配置里面,让本就很冗长的pom.xml变的更加的冗长,不喜欢。
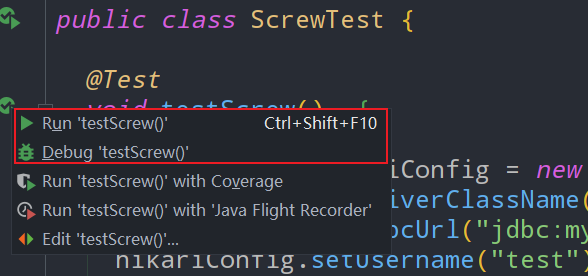
所以maven插件的这种方式我就不给大家演示了,直接把下面的代码Ctrl + C/V到你的src/test/java目录下。简单的修改配置,运行就可以了
import cn.smallbun.screw.core.Configuration;
import cn.smallbun.screw.core.engine.EngineConfig;
import cn.smallbun.screw.core.engine.EngineFileType;
import cn.smallbun.screw.core.engine.EngineTemplateType;
import cn.smallbun.screw.core.execute.DocumentationExecute;
import cn.smallbun.screw.core.process.ProcessConfig;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import org.junit.jupiter.api.Test;
import javax.sql.DataSource;
import java.util.ArrayList;
public class ScrewTest {
@Test
void testScrew() {
//数据源
HikariConfig hikariConfig = new HikariConfig();
hikariConfig.setDriverClassName("com.mysql.cj.jdbc.Driver");
hikariConfig.setJdbcUrl("jdbc:mysql://127.0.0.1:3306/database");
hikariConfig.setUsername("db-username");
hikariConfig.setPassword("db-password");
//设置可以获取tables remarks信息
hikariConfig.addDataSourceProperty("useInformationSchema", "true");
hikariConfig.setMinimumIdle(2);
hikariConfig.setMaximumPoolSize(5);
DataSource dataSource = new HikariDataSource(hikariConfig);
//生成配置
EngineConfig engineConfig = EngineConfig.builder()
//生成文件路径
.fileOutputDir("d://")
//打开目录
.openOutputDir(true)
//生成文件类型:HTML
.fileType(EngineFileType.HTML)
//生成模板实现
.produceType(EngineTemplateType.freemarker)
.build();
//忽略表
ArrayList<String> ignoreTableName = new ArrayList<>();
ignoreTableName.add("test_user");
ignoreTableName.add("test_group");
//忽略表前缀
ArrayList<String> ignorePrefix = new ArrayList<>();
ignorePrefix.add("test_");
//忽略表后缀
ArrayList<String> ignoreSuffix = new ArrayList<>();
ignoreSuffix.add("_test");
ProcessConfig processConfig = ProcessConfig.builder()
//指定生成逻辑、当存在指定表、指定表前缀、指定表后缀时,将生成指定表,其余表不生成、并跳过忽略表配置
//根据名称指定表生成
.designatedTableName(new ArrayList<>())
//根据表前缀生成
.designatedTablePrefix(new ArrayList<>())
//根据表后缀生成
.designatedTableSuffix(new ArrayList<>())
//忽略表名
.ignoreTableName(ignoreTableName)
//忽略表前缀
.ignoreTablePrefix(ignorePrefix)
//忽略表后缀
.ignoreTableSuffix(ignoreSuffix).build();
//配置
Configuration config = Configuration.builder()
//版本
.version("1.0.0")
//描述,文档名称
.description("数据库设计文档生成")
//数据源
.dataSource(dataSource)
//生成配置
.engineConfig(engineConfig)
//生成配置
.produceConfig(processConfig)
.build();
//执行生成
new DocumentationExecute(config).execute();
}
}在测试用例里面运行上面的代码,就会自动生成数据库文档到fileOutputDir配置目录下。
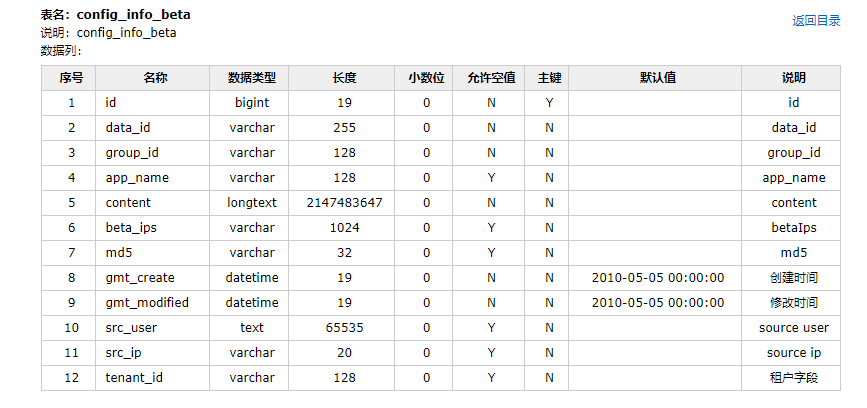
五、效果

原文链接:https://www.cnblogs.com/zimug/p/13431093.html